SBI – Department of Systems Biology and Bioinformatics Faculty of Computer Science and Electrical Engineering University of Rostock Ulmenstrasse 69 | 18057 Rostock Germany +49 381 498-7571 olaf.wolkenhauer@uni-rostock.de
Data Science, Big Data, Deep Learning, Maschinelles Lernen und Künstliche Intelligenz
This page is in German, for an English summary/flyer, please click here.
Der technologische Fortschritt in den Lebenswissenschaften ist eng mit der Generierung immer komplexerer Daten verbunden, deren Analyse und Interpretation oftmals nur noch durch computergestützte Werkzeuge der Informations- und Kommunikationstechnik und mit Hilfe ausgefeilter mathematischer Methoden geleistet werden kann. Mit einer stetig wachsenden Vielfalt und Menge an Daten ergeben sich jedoch auch neue Möglichkeiten, die sich im Kontext “Data Science" zunehmend klarer präsentieren. Der Begriff “Data Science” beschreibt hier die Extraktion von Wissen aus Daten.
Aufgrund Komplexität von Krankheiten und unmittelbaren Relevanz für jeden Einzelnen und der Gesellschaft im Ganzen, zeigt sich das Potential dieser digitalen Transformation im Gesundheitssystem besonders deutlich. So entwickelt sich die Strukturierung und Auswertung komplexer Daten mit Hilfe der Bioinformatik und systembiologischer Ansätze bereits seit einigen Jahren (a) zu einer der fundamentalen Säulen bei der Gewinnung neuer Erkenntnisse in der medizinischen Forschung, (b) zu einer vielversprechenden Möglichkeit bestehende Versorgungsstrukturen zu optimieren und ihre Abläufe effizienter zu gestalten, sowie (c) zu einer zuverlässigen Hilfe für Ärzte und Patienten hinsichtlich diagnostischer, prognostischer und therapeutischer Entscheidungen.
Unser internationales Team, bestehend aus ~20 Mitarbeiter-Innen mit umfassender Expertise in verschiedensten Natur- und Lebenswissenschaften (Informatik, Mathematik, Ingenieurwissenschaft, Physik, Biomedizin, Biotechnologie und Molekularbiologie), organisiert sich selbstständig und in flachen Hierarchiestrukturen. Dieser interdisziplinäre und dynamische Ansatz unterstützt uns seit über 20 Jahren bei der effektiven Translation biologischer und medizinischer Forschungsergebnisse in praktische Anwendungen und industrierelevante Lösungen.
Wir sind regelmäßig für Ministerien und Forschungsförderer im In- und Ausland beratend tätig, wodurch wir weltweit Einfluss auf die strategische Ausrichtung der interdisziplinären Forschung in den Lebenswissenschaften ausüben können - eine verantwortungsvolle Aufgabe, die wir gewissenhaft und mit Freude übernehmen. Durch unsere weltweite Lehrtätigkeit an Universitäten und außeruniversitären Einrichtungen, sowie die Veröffentlichung von Fachbüchern leisten wir einen Beitrag zur Förderung des wissenschaftlichen Nachwuchses, deren kreativste, intelligenteste und motivierteste Köpfe wir jederzeit gerne in unserem Team begrüßen.
Die Kompetenzschwerpunkte unserer Arbeitsgruppe sind:
Netzwerk- und Prozessanalysen mit Methoden der Systemtheorie
Mustererkennung und Bildanalysen mit Methoden des maschinellen Lernens
Algorithmen für Entscheidungssysteme
Integration, Analyse und Visualisierung von heterogenen Datensätzen
Im Folgenden beschreiben wir ausgewählte Beispiele von Projekten mit Anwendungen in der Klinik und in Kooperation mit Unternehmen. Auf unseren Webseiten finden sie ebenfalls eine vollständige Beschreibung von unseren Projekten, Publikationen, Workshops und Lehraktivitäten.
Maschinelles Lernen mit klinischen Patientendaten zwecks Stratifizierung
Durch die Identifizierung von relevanten Schlüsselmerkmalen und der Klassifizierung umfassender Patientendaten mit Hilfe von überwachten und nicht-überwachten maschinellen Lernalgorithmen war es uns möglich bereits vor medizinisch indizierten Herz-Bypass-Operationen mit einer Genauigkeit von über 80% vorherzusagen, ob eine zusätzliche Stammzellbehandlung der Patienten zu einer Verbesserung der Herzfunktion nach der OP führen wird. Zur Vorhersage des Behandlungsergebnisses anhand der wichtigsten klinischen Merkmale wurden die Algorithmen AdaBoost, Support Vector Machines und Random Forrest angewendet; zur Patientenklassifizierungen wurde weitere unabhängige Algorithmen (t-SNE) eingesetzt, damit Patienten mit dem gleichen Behandlungsergebnis visuell durch Dimensionsreduktion der Parameter bestimmt werden können. Durch die Kombination dieser Ansätze gelang es uns eine diagnostische Biomarkersignatur im peripheren Blut von Patienten zu identifizieren, die eine präoperative Abschätzung hinsichtlich des therapeutischen Erfolgs ermöglicht und somit die Chancen auf eine langfristig verbesserte Herzfunktion erhöhen.
Aktuell verwenden wir computergestützte Analysen zur verbesserten Interpretation von medizinischen Bildern. Jüngste Fortschritte im Bereich des Deep Learning - speziell bei den sog. Convolutional Neural Networks (CNNs) - haben einen großen Sprung zu sinnvollen unterstützenden Anwendungen ermöglicht, indem sie Objekte und Muster in medizinischen Bildern automatisiert segmentieren, identifizieren und quantifizieren. In einem unserer aktuellen Projekte verwenden wir Magnetresonanztomographie(MRT)-Aufnahmen des Herzens, um mit Hilfe spezieller Algorithmen die zugrunde liegende kardiale Funktionalität und den jeweiligen Gesundheitszustand des Patienten optimal zu bewerten.
Ziel des Projektes ist die Entwicklung eines Ansatzes zur Identifikation von krankheitsrelevanten molekularen Mechanismen, die sowohl für die entzündliche Darmerkrankung Colitis ulcerosa (UC), als auch bei der Schizophrenie (SCZ) von Bedeutung sind. Zu diesem Zweck entwickeln wir eine neue systemmedizinische Herangehensweise für die Konstruktion eines mehrdimensionalen Modells, mit deren Hilfe eine mögliche gestörte Kommunikation zwischen dem Magen-Darm-Trakt und dem zentralem Nervensystem aufgezeigt werden soll.
Das initiale Modell wird zunächst unter Berücksichtigung bereits bekannter Risikofaktoren aus genomweiten Assoziationsstudien und neu zu identifizierender Risikofaktoren aus projektinternen, transkriptomweiten Assoziationsstudien für UC und SCZ generiert. Für die Modellerweiterung werden RNA-Sequenzierungs Daten von UC und SCZ Patienten sowie gesunden Kontrollindividuen in Verbindung mit den genetischen Daten ausgewertet und mit Hilfe von Methoden der Bioinformatik und mathematischen Modellierung zu einer krankheitsübergreifenden Interaktionskarte vereint. Dieser integrative Ansatz erlaubt es uns mögliche gestörte molekulare Mechanismen der Kommunikation zwischen Magen-Darm-Trakt und zentralem Nervensystem aufzuzeigen. Ein konkretes Ziel ist hierbei die Identifizierung von Zielgenen und molekularen Mechanismen, um in nachfolgenden funktionellen Laborexperimenten effektive Therapien für psychische Krankheiten und chronisch-entzündliche Darmerkrankungen zu entwickeln.
Methoden des maschinellen Lernens für therapeutische Entscheidungen
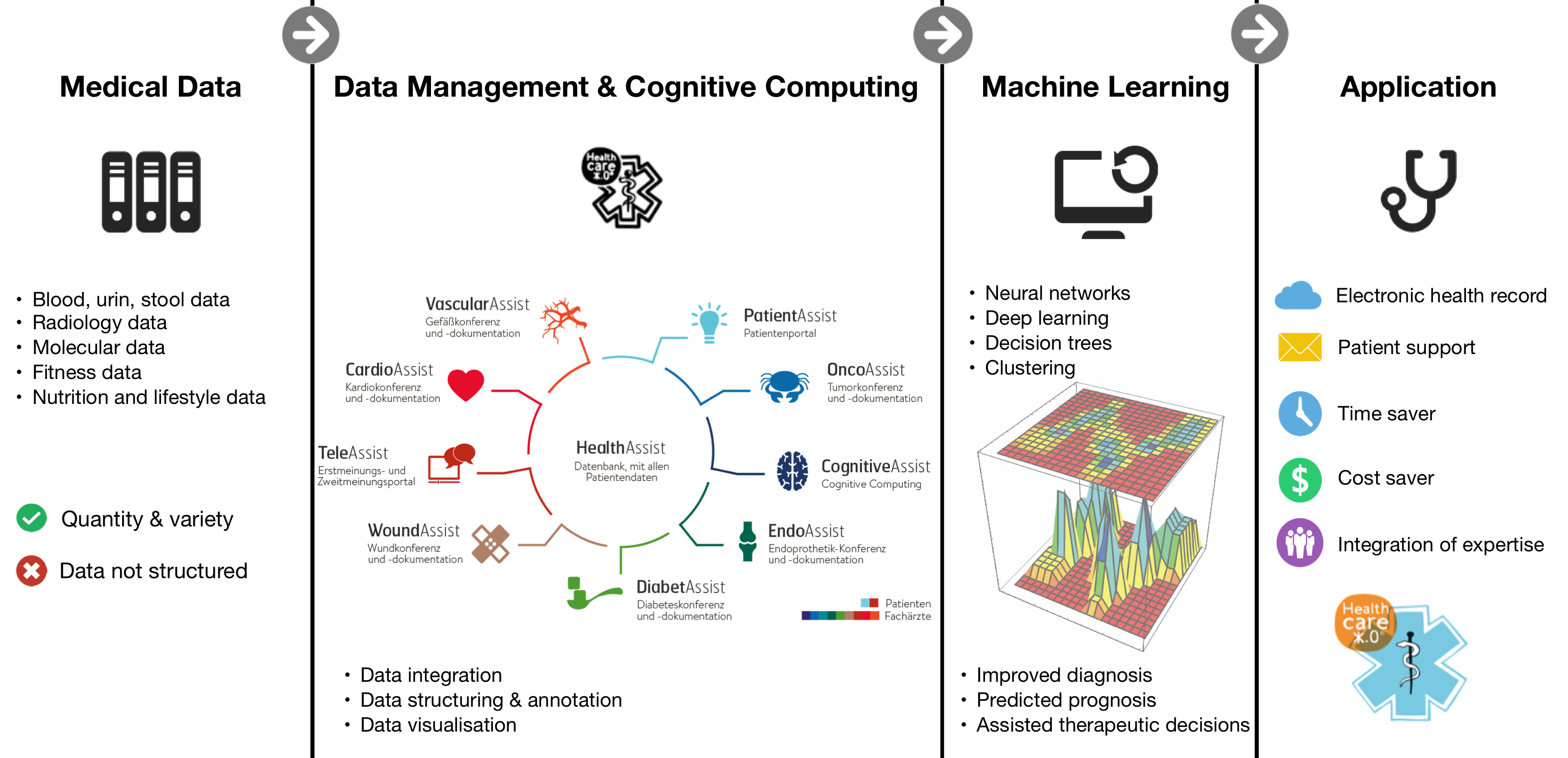
Gemeinsam mit unserem Kooperationspartner aus dem IT-Bereich geht es um den Einsatz von Methoden der künstlichen Intelligenz (KI) zur Unterstützung von diagnostischen, prognostischen und therapeutischen Entscheidungen. Schwerpunkte liegen dabei auf: Integration, Visualisierung, Filterung und Konsolidierung heterogener Datensätze; Konzeption einer KI für das Klassifizieren und Gruppieren von Patienten aus bestehenden sowie neu generierten Datensätzen; Umsetzung der erlernten Informationen in prädiktive Algorithmen unter Berücksichtigung von internationalen medizinischen Leitlinien. Ein weiterer Schwerpunkt ist die Integration von breit gefächerten Datentypen und die Identifizierung entscheidender prädiktiver Faktoren.
Ein Problem existierender Systeme der Informatik für die Interpretation medizinischer Daten ist die Zuverlässigkeit der Aussagen, die durch große Varianzen in den Daten selbst verringert sein kann. Ein Ansatz zur Lösung dieses Problems ist unter anderem eine adäquate Gewichtung der Evidenz, sowie der auf ihr basierenden Vorhersagen anhand von Methoden aus der präskriptiven Entscheidungstheorie. Mit ihrer Hilfe soll der Arzt dabei unterstützt werden seine Entscheidungen rationaler zu gestalten zu können, um so beispielsweise Wirkungen und Nebenwirkungen von Medikamenten in Relation zum Gesamtsystem zu betrachten.
Identifikation diagnostischer und therapeutischer Marker
Komplexe Erkrankungen, wie beispielsweise Krebs oder Entzündungen, können als Netzwerke interagierender Biomoleküle dargestellt werden. Die Analyse dieser Netzwerke, sowohl für ein besseres mechanistisches Verständnis des Krankheitsverlaufs als auch zur Identifikation diagnostischer und therapeutischer Marker, stellt die Wissenschaft aufgrund (i) der großen Anzahl experimentell validierter Interaktionspartner; (ii) der vielschichtigen Regulationsebenen; (iii) der nicht-linearen Natur von dynamischen Interaktionen; und (iv) der großen Anzahl an Rückkopplungsmechanismen vor große Herausforderungen.
Zur Identifikation des regulatorischen Kerns großer Netzwerke, die beim Übergang vom gesunden zum erkrankten Phänotyp beteiligt sind, haben wir einen integrativen ‚Workflow‘ entwickelt, der als innovatives Element zur Reduktion der relevanten Netzwerkkomponenten ein spezielles Optimierungskonzept verwendet. Basierend auf der Topologie des Netzwerkes sowie phänotyp-spezifischer „Omics“-Daten können so regulatorische Elemente identifiziert und entsprechend ihrer Bedeutung gewichtet werden.
Dieser ‚Workflow‘ konnte bereits erfolgreich zur Vorhersage spezifischer Krankheitssignaturen und entsprechender therapeutischer Zielstrukturen im Kontext der Metastasenbildung bei Blasen- und Brustkrebs eingesetzt und experimentell validiert werden. Aktuell findet der ‚Workflow‘ Anwendung zur Identifizierung von molekularen Schlüsselsignaturen (i) bei akuter Entzündung; sowie (ii) bei Fettleibigkeit-induzierten entzündlichen Prozessen.
Maschinelles Lernen für diagnostische Entscheidungen
Das Differentialblutbild zur Quantifizierung von Blutzellen ist eine wichtige Routineuntersuchung in der medizinischen Labordiagnostik, die gewöhnlich durch die Anwendung von fluoreszenz-markierten Chemikalien realisiert wird. Ziel des Projektes ist die Entwicklung einer neuen Methode zur Bestimmung vom Differentialblutbild, die auf Basis einer computerunterstützten Mustererkennung von Zellen eine fluoreszenz-freie Analyse ermöglichen soll. Die Grundlage der Mustererkennung stützt sich dabei auf der bildgebenden Durchflusszytometrie, die detaillierte Bilder einzelner Blutzellen im Hochdurchsatz-Verfahren ermöglicht.
Für die Realisierung dieser Methode entwickeln wir computergestützte Prozessabläufe (‚Workflows') mit auf maschinellem Lernen basierte Bildanalysen für die Klassifizierung der aufgenommenen Zellbilder. Da diese Methode weniger Laborarbeit erfordert, ist sie schneller und kostengünstiger als die aktuell angewendete und somit eine effiziente Unterstützung in den Klinken bei der Beantwortung diagnostischer Fragestellungen, beispielsweise zur Identifikation von Krankheiten wie Infektionen oder Autoimmunerkrankungen.
Auf unserer Webseite finden sich auch weitere Informationen zu unserem Team, Projekten und Expertisen.
Maschinelles Lernen für unausgeglichene Datensätze
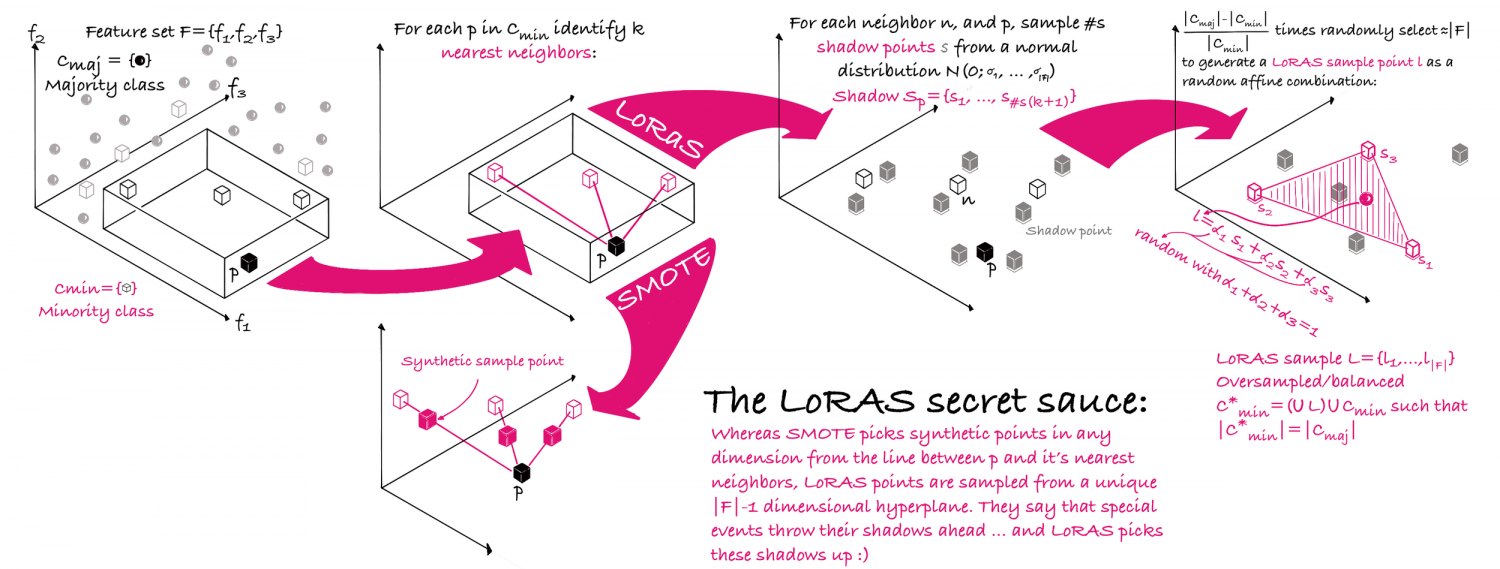
In realen Szenarien sind Datensätze oft unausgewogen. Das heißt, die Datensätze, die für das überwachteLlernen bestimmt sind, teilen sich in Klassen auf, in denen es in einigen Klassen im Vergleich zu den anderen eine sehr große Anzahl von Instanzen gibt. Das Training von maschinellen Lernalgorithmen auf solchen Daten ist eine Herausforderung. Eine der wichtigsten Forschungsrichtungen in diesem Bereich ist die Anwendung von Oversampling und Undersampling, um die Daten auszugleichen und daraus zu lernen. Die Synthetic Minority Oversampling Technique (SMOTE) ist der Pionier vieler anderer effektiver Oversampling-Techniken. Wir gehen auf ein grundlegendes Problem des SMOTE-Algorithmus ein, d.h. SMOTE Oversampling nicht einheitlich den gesamten Datenverteiler und konzentriert sich daher nicht auf eine ausreichend gute Approximation des Datenverteilers. Die Grundidee unseres Algorithmus Localized Randomized Affine Shadowsampling (LoRAS) ist es, den Datenverteiler der Minderheitenklasse lokal zu approximieren und Proben aus dem lokal approximierten Datenverteiler für das Oversampling zu entnehmen. Beim Testen von LoRAS auf einigen öffentlich zugänglichen Datensätzen können wir feststellen, dass die verbesserten Modellleistungen im Vergleich zu mehreren modernen Oversampling -lgorithmen deutlich verbessert wurden.
Digitale und makroanatomische Untersuchung pulmonaler arterieller und venöser Strukturen der Lunge
Im klinischen Alltag beobachten Thoraxchirurgen oft Varianten der Lungenanatomie, die in Fachbüchern bis dato nicht abgedeckt sind. Dies können unterschiedliche Strukturen des Bronchius sein - wann und wo spalten sich die Atemwege zu den einzelnen Lappen ab? - wie auch die Art, in der eine Arterie sich um den Bronchius legt. Diese Varianten sind selten, doch für einen Chirurgen entscheidend in der Operationsplanung. Gemeinsam mit der Abteilung für Thoraxchirurgie der Universitätsmedizin Rostock und der Firma Fujifilm haben wir es uns als Ziel gesetzt, diese Abweichungen zu finden, zu klassifizieren und sie dem operierenden Arzt an die Hand zu geben.
Ausgangspunkt unserer Arbeit sind CT Thorax Scans, aus denen bereits Masken extrahiert wurden - die Lungenlappen, Bronchius, Arterien und Venen. Wir verarbeiten diese Masken zu Baumstrukturen und versuchen, in diesen Muster zu finden und zu gruppieren. Wir möchten einen Klassifikator entwickeln, der neue Patientendaten automatisch einer Gruppe zuordnen kann. Diesen Klassifikator wollen wir Chirurgen zu Verfügung stellen, damit sie sich einen schnellen Überblick über die anatomischen Besonderheiten eines Patienten verschaffen können. Desweiteren erhoffen wir uns, einen Überblick über die Prävalenz der gefundenen Variationen zu erlangen.